Compute Moonshots: Harnessing New Physics
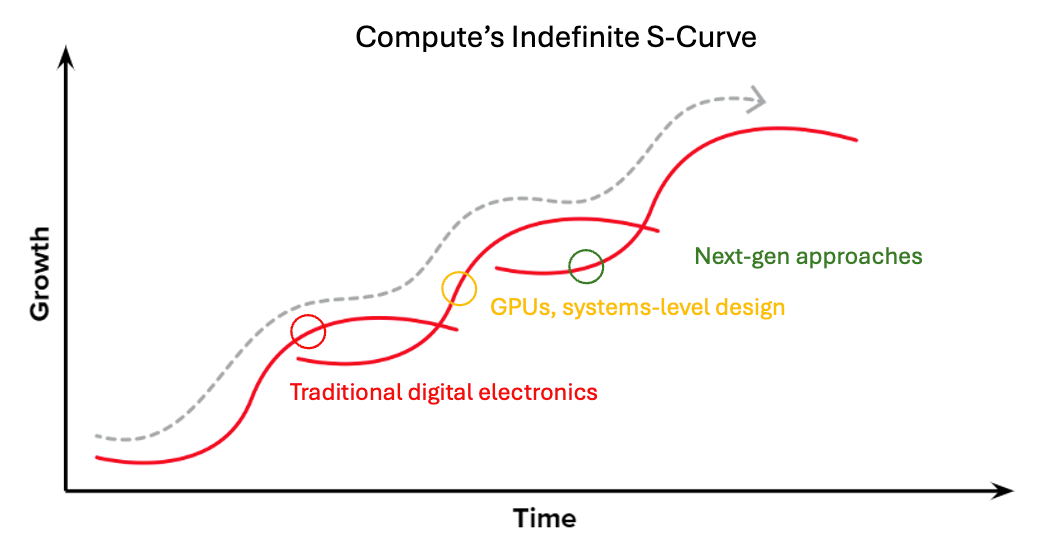
The digital computing domain is reaching relative maturity, with traditional electronics well into the final phase of their S-curve and GPUs in the middle of theirs. At the same time, demand for compute shows absolutely no sign of slowing, with AI workloads & other HPC going parabolic followed by desired edge applications in embodied intelligence and IoT. Next-gen approaches that harness entirely different materials systems with more amenable physics promise moonshot solutions to these problems.
“The reports of my death are greatly exaggerated” – Moore’s Law
After eight decades, the physics of traditional digital electronics are increasingly enforcing fundamental limits on their speed and efficiency. Electrons are slow and resistive, trapping them in one place for storage requires continual energy, deterministic binary computation necessitates extreme redundancy, and the von Neumann bottleneck (i.e. transporting bits back and forth from energy to compute) comes with efficiency & latency costs as well as limits parallelism and tradeoff between memory throughput and capacity.
We’ve already neared the physical limits of placing gates closer to each other on silicon. Clock speed performance and energy density / efficiency plateaued in the 2000s.
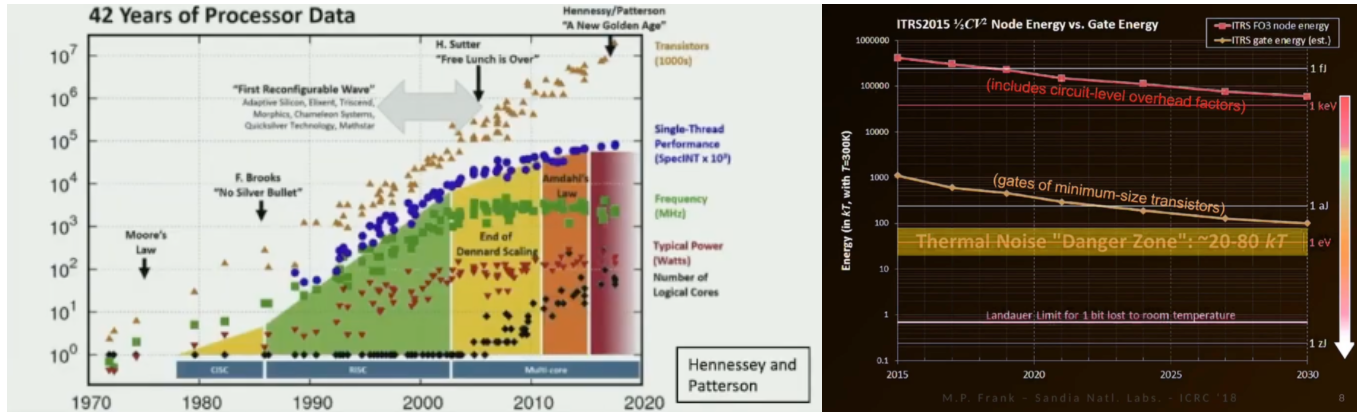
As the physics has become harder to work with, costs and complexity to make chips have gone vertical, underscoring the diminishing returns.

Finally, the density of memory technology has slowed just as AI places exponentially growing demands on it.
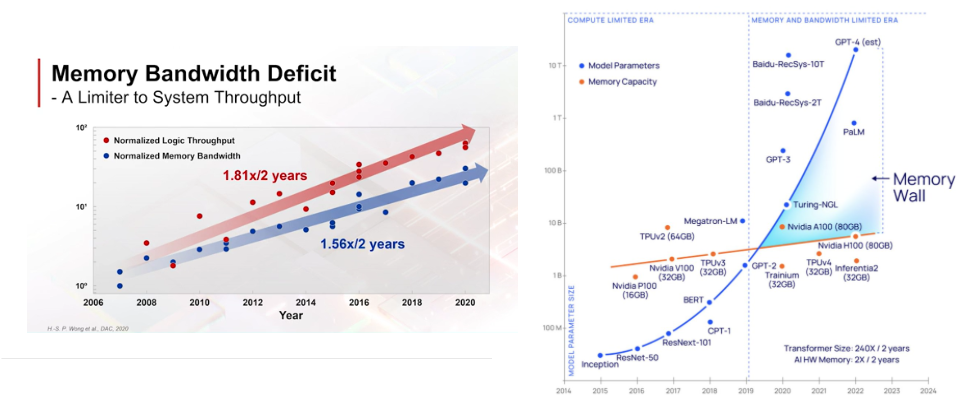
It’s not that Moore’s Law is dead in the water. People have been calling for the death of Moore’s Law for decades. There’s still a decade-plus of clearly-defined runway to improve digital compute performance when viewed more holistically. Here’s a subset of the innovations on the horizon:
- New materials: diamond, III-V and III-N compound semiconductors, glass substrates
- Memory: future generations of HBM or CXL, stacking DRAM directly on top of the GPU, hybrid bonding, photonic interconnects (from inter-rack to inter-GPU co-packaged optics and eventually to inter-chiplet), new non-volatile memory
- Process: backside power, GAA then CFET then 2D TMD and then carbon nanotubes, 3D packaging, SDA, High-NA EUV
- Systems-level design: building AI’s sparsity into GPU hardware, chip designs specific to a given model, wafer-scale chips, data center liquid cooling, datacenters as the new unit of compute, even multi-datacenter training
The point is rather that while the industries’ $100B+ in annual R&D spend will ensure that compute performance’s trend line continues marching upward, each successive engineering miracle needed to overcome the ever-gnarlier physics of digital approaches will increasingly tilt the incentive towards finding systems with entirely different physics.
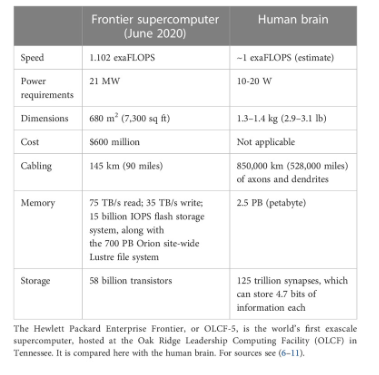
There's plenty of headroom for progress given that cutting edge digital processors are still 1M times more energy inefficient than the brain.
Moonshot Approaches Harnessing New Physics
Thankfully, many promising moonshots with high technological readiness are brewing across physical systems from photonics to quantum to in-sensor and end uses from AI data centers to ultra-low energy edge intelligence. All of the below promise possible efficiency gains of orders of magnitude.
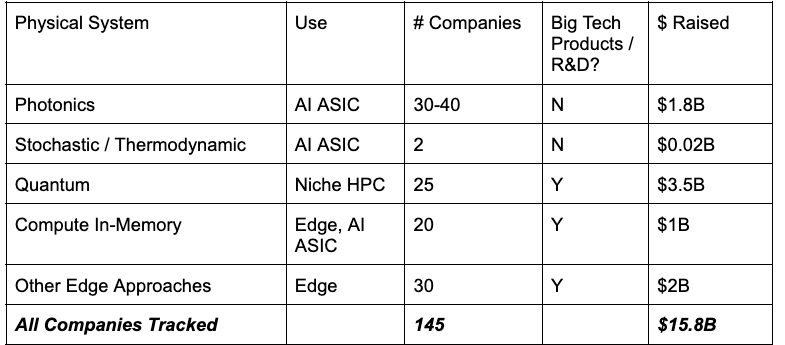
Looking at the list, you'll notice these compute approaches are almost all analog approaches, which are notoriously difficult as they suffer from minimal CAD software or programming tools, lack of error correction, device-device variability in manufacturing, among other issues. Moreover, the analog processing still needs to be converted to digital and some portion of even matrix multiplication dominating AI computations always has to be done digitally, which often negate analog systems’ performance benefits in the first place and creates all kinds of difficulties in practice designing a chip that cohesively maps software to heterogeneous compute systems. In other words, all analog approaches still have digital components which weaken performance advantages and complicate design.
Finally and more optimistically, if AI keeps going towards lower and lower precision (e.g. FP1), analog circuits’ lower accuracy will become less problematic.
1. Datacenter AI Accelerators
Data center AI accelerators have the most value capture of today’s applications and are going after a ~$50B market growing rapidly. They currently hold the highest leverage position in the supply chain; and, startups can readily vertically integrate and then pose a direct, existential threat to the third most valuable company on earth. This is more true the more “out there” the approach is, as Nvidia is well acquainted with compute in-memory and traditional photonics approaches but is less likely to have anyone working on free space optical beams projecting onto a metasurface. An unexpected moonshot that works would garner a higher premium in an acquisition than a well-studied approach that incumbents could more easily replicate internally.
It is, of course, a correspondingly difficult challenge. To have a shot at assailing Nvidia’s moats in software, distribution, its 1-year product release and its 2.5-year performance doubling cadences, a startup must harness physics that grant it a realistic path on paper to ~100x efficiency improvement over today’s H100s. Because, that 100x theoretical or "on paper" advantage may actually be 25x in practice. And, by the ~6-8 years it takes even the top chip startups to get a product to market, Nvidia's already churned through 6-8 product cycle upgrades. That 25x practical advantage is now only ~10x the SotA Nvidia chips at launch. That's barely good enough to get a significant chunk of customers to switch to an unproven startup with weak software and an uncertain path towards subsequent products.
If it does happen and the startup is able to continually release improved products, a 10-20% terminal market share is reasonable to expect.
Another concern that investors and entrepreneurs rightfully have over startups’ competitive prospects is that Nvidia’s most unassailable moat isn’t their hardware but their software. One option is to take on that burden themselves, vertically integrating and owning the whole stack. Cerebras Systems, an SRAM-heavy architecture looking to go head-to-head with Nvidia for LLM inference, did so in a correspondingly capital intensive way by having 80% of their large employee base be software developers building compilers, drivers, debuggers, etc. customized to their new chip architecture. As an executive said, “the hardware is hard, the software is harder.”
George Hotz’s tinygrad, seeking to compete on a smaller scale for a subset of workloads, is taking a software-defined but capital-light approach. His tiny team is writing a maximally minimalist, simple and efficient software stack built from the ground up for deep learning. He’s using commodity hardware at first and only later verticalizing into their own chip designs.
Alternatively, one may be able to outsource the software to Nvidia’s highly incentivized competitors. We at Compound have spoken with several companies looking to strike deals with Nvidia competitors to embed their alternative physics approach alongside the competitor’s GPU/CPU and then utilize that company’s software stack.
Finally, model providers and cloud providers are focused on building the infrastructure to abstract away the complexities of the underlying compute, offering multiple providers and prioritizing the most performant.
Ultimately, we believe that there’s little reason to switch from Nvidia to AMD for slightly worse hardware and significantly worse software at a similar price. However, if a company actually delivers 10x+ higher performant hardware harnessing entirely new physics, there are ways to make the software palatable.
Computing with Light
Photonic computing makes intuitive sense as light travels 200x faster relative to electricity with no resistance. However, it’s incredibly difficult to bend to get nonlinearities, doesn’t stay still so storage isn’t an option, and requires large energy hungry components like lasers that can’t be shrunk past the mm size.

Several dozen companies have spun out of top labs over the last decade with DARPA contracts and $1.8B in VC funding, and have effectively all pivoted their core focus to on-die interconnects – a business with no leverage over the chip makers whom they must interconnect with but a technology that’s commercializable in the next 3-5 years and that may meaningfully alleviate the von Neumann bottleneck and ironically make integrated photonics less necessary.
Because the components can’t be miniaturized indefinitely, the field depends on parallelism via some combination of wavelength, space, time, polarization, and mode. Top first generation companies like Lightmatter achieved two degrees of parallelism. Exciting recent papers have added a third. Additionally, while most approaches instantiate the neural network as meshes of waveguides, a particularly exciting approach combines free space optics and a metamaterial to do as much computation as possible entirely in light to avoid repeatedly converting to electronics. Given integrated photonics’ difficulty scaling, creative approaches like this make the most sense. They have a very real, though binary and of course low probability shot at taking on Nvidia.
Computing with Heat
Thermodynamics or stochastic computing harnesses noise as its means of computation instead fighting it by brute forcing determinism via redundancy. If you can’t beat em, join em.

This new field pioneered by two recent startups has Normal taking a more measured, iterative approach and Extropic going for it all: a fully generalized, programmable energy-based model.
2. Niche HPC Workloads
Computing with Quantum Mechanics
Quantum computing is useful for applications with a limited number of inputs and outputs but massive complexity in the interactions and correlations amongst inputs that yield a combinatorial explosion of possible outputs. The classic examples are prime number factoring; many body quantum mechanics for chemistry, drug discovery and materials science; condensed physics; and, some optimization and search problems.
Interestingly, despite the ~$4B in funding into hardware startups, the industry boasts relatively few concrete examples of what such computers could actually be useful no less necessary for. It may simply be an empirical question to be determined once effective quantum computers can be tinkered with.
Another interesting industry contradiction is that while several startups have recently collected billions in public money to build utility scale computers, the limited scale of current demonstrations puts into question the efforts’ feasibility. The optimist's take is that quantum hardware finally seeing the light at the end of the tunnel will fuel efforts to make them useful and that combined with efforts to make quantum algorithms more amendable to smaller machines will pull forward their practical deployment. FWIW 35% of quantum researchers expect the hardware to be more useful within 5 years and another 37% say 6-10 years.

3. Edge Intelligence
These approaches are for applications where energy usage places a highly restrictive bottleneck. Applications range from iPhones to robotics to autonomous vehicles to IoT devices. While dozens of companies have been launched around bringing to market ultra-low energy edge intelligence chips, the impetus is on finding PMF in an application with enough demand pull to sustain customized chips.
Computing In-Memory
This direct alternative to the von Neumann architecture harnesses the fact that reading and writing to memory requires orders of magnitude more energy than the math operations. The data remains stored in non-volatile memory cells while computations are performed “in-memory” by manipulating their states directly. The states include resistance, charge, polarization or spin for ReRAM/memristors, SRAM/DRAM/PCM, FeRAM, and magnetic approaches, respectively.
The technology can also be applied to AI servers, with nearly half the CIM startups doing so.

Neuromorphic
In efforts to mimic the brain, these approaches use some combination of compute in-memory, spiking neurons to avoid the energy cost of constraining electrons in storage, extremely dense connectivity, and asynchronous and highly parallelized processing. While it’s intuitive that someone someday will figure out how to make these work, the compounding failure modes of combining multiple non-traditional approaches likely explain the lack of startup success so far and why even Intel’s neuromorphic chip hasn’t been a commercial success.
Computing In-Sensor
The age of IoT, robots, and autonomous vehicles will require astounding sensory processing. In-sensor computing maximally compresses the incoming information in the same way that the humans’ sensory circuits compress the 10M bits of incoming data / second by 200,000x to fit within the brain’s 50 bit / second conscious processing capacity. They sense raw data and process it on-chip in analog optical or auditory matrix arrays or metamaterials. They then pass along only the minimal necessary information (e.g. feature extraction, classification) to the cloud, the AV’s digital computers, etc. For example, all the processing to determine that a person is walking in front of the car may take place in specially designed chips with only a short binary code being transmitted.

- Low energy, high performant visual processing for robotics, quality control, automotive, etc.
- Ultra-low energy, always-on monitors for specific voice commands, voice command processing, home / car safety (e.g. keying for the sound of glass breaking or car crash)
4. Other Moonshot Compute Methods
Other exciting methods include reversible computing which aims for negligible information / energy loss as the transistors switch states to perform computations; magnetics, magnons, ferroelectrics, spintronics, and valleytronics; brain organoid-based computing which have reached the neuron count of fruit flies; a few other biological approaches; and, information-secure architectures for AI servers.
From an ethos perspective, we are intrigued by these types of approaches as they have perhaps the most convexity as investments but the least learnings thus far due to their novelty and few approaches by for-profit entities.
It’s Time to Take the Shot
Startups are classically positioned to bring these new physics approaches to market, because they don’t have to worry about undermining their trillions in cumulative investment in digital computing and can move faster than decades-old bureaucracies with tens to hundreds of thousands of employees.
Like any new compute architecture, the approaches above will be judged on the formula below. GPUs handily won the first wave of HPC due to their far higher performance with still strong generality. However, maybe in the next ten years the market will accept lower generality in exchange for step functions in performance as the model architectures standardize and use cases mature.

In such a world, chips custom built specifically for inference, for tasks that require different algorithmic structures like CNNs for visual data vs Transformers vs optimization algo’s, for use cases with different accuracy requirements like medical vs consumers generating goofy haikus, for 3B vs 300B vs 30T parameter models, for edge intelligence, etc. may thrive. That dynamic would tilt the industry structure from an oligopoly to one with merely extreme power laws.
Or, maybe it’s foolish to bet that the current algorithms will reign supreme, remaining reasonably untouched in structure for years to come and that the industry won’t continue to value above all else the flexibility of responding to whatever may be on the horizon. Building chips custom made for 100M-parameter RNNs or LSTMs ten years ago would’ve been money down the drain.
However, it may well be different this time around. While LLMs will likely add in some kind of discrete problem search like MCTS to build in genuine logical reasoning, the Transformer architecture is obviously “good enough” by itself and we may well get the blended Transformer / MCTS architecture within a year with GPT5.
Moreover, hardware specialization may now make sense since unlike the last AI cycle we actually have clearly defined use cases for the compute and thus know what to optimize for. The first-order use cases are already markets pulling in many billions of dollars and could thus certainly support specialized chips (LLMs, AVs, smartphone and laptop edge intelligence, etc.). As new use cases emerge, existing ones further solidify and PMF becomes more nuanced, the industry should march towards further specialization as is typical in the maturation of industries.
Either way, both the supply and demand pressures make it well worth taking the shot now as the ever-gnarlier physics of traditional digital compute yields diminishing returns just as the AI server market rapidly ascends the ranks of largest markets in the world and as robots, AVs and IoT become increasingly infused in our lives.
Another potential inflection point for alternative physics approaches may come in the not-too-distant future with political and societal upheaval over AI’s continent-scale, exponentially-growing energy demand places a hard ceiling on continued scaling in the not distant future.
We at Compound have gone down the rabbit hole on each of these approaches and are thrilled to meet teams exploring new physical systems.